Word Vectors and AI Prophets: The Church of GPT
This post contains content that could be viewed as sacrilegious. To be clear, I am not criticizing any particular beliefs or denomination. Enjoy!

This project is available here provided it hasn’t crashed or something…
Religion Is Weird…
Broadly speaking, religions/religious beliefs have some interesting emergent qualities. One of the common ones I’ve identified is theophanies, or visions of heavenly beings. This most commonly happens with Christian flavors of belief. Some exemplary examples are the LDS church, Seventh Day Adventist, and other churches formed during the “Great Awakening”. Given how prevalent visions are in Christian religion, I wanted to see how similar these different theophanies are to each other using sentence embeddings.
What Are Sentence Embeddings?
Sentence embeddings are a hot topic right now with generative AI language models and different RAG (Retrieval Augmented Generation) systems. A sentence embedding is a vector or numerical representation of a sentence. Depending on the content of the sentence, the vector will be in a specific spot within the embedding space. At first, this can be a hard concept to grasp, but here’s a chart that illustrates how word embeddings work on a smaller scale.
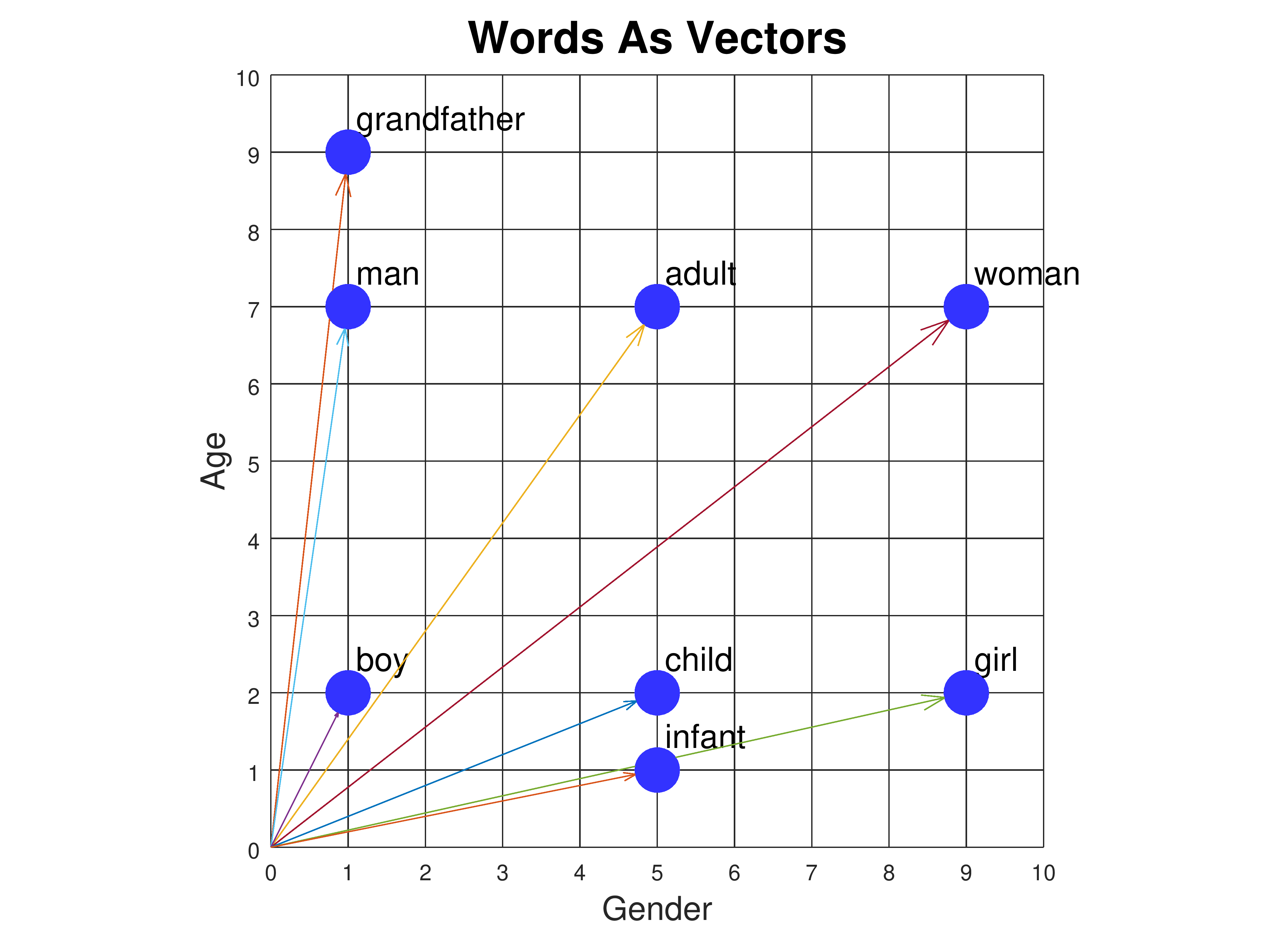
In this example, there are only 2 dimensions, which means we can only represent words in terms of gender and age, but imagine if there were 1500 dimensions. Then we can represent words in all sorts of ways.
The neat thing about these vectors is that we’re able to perform different mathematical operations on them quite consistently. One famous example is taking the vector for the word King, subtracting the vector for Man from it, and adding back Woman. The resulting vector is really close to the vector for Queen.
King - Man + Woman ≈ Queen
For this project I utilized a concept called cosine similarity. The cosine similarity between 2 vectors shows how similar the vectors are with each other.
One may think that euclidean distance might be good enough for this, but in higher dimensional spaces euclidean distance tends to break down and not be a good indicator of similarity. That is why we use cosine similarity instead.
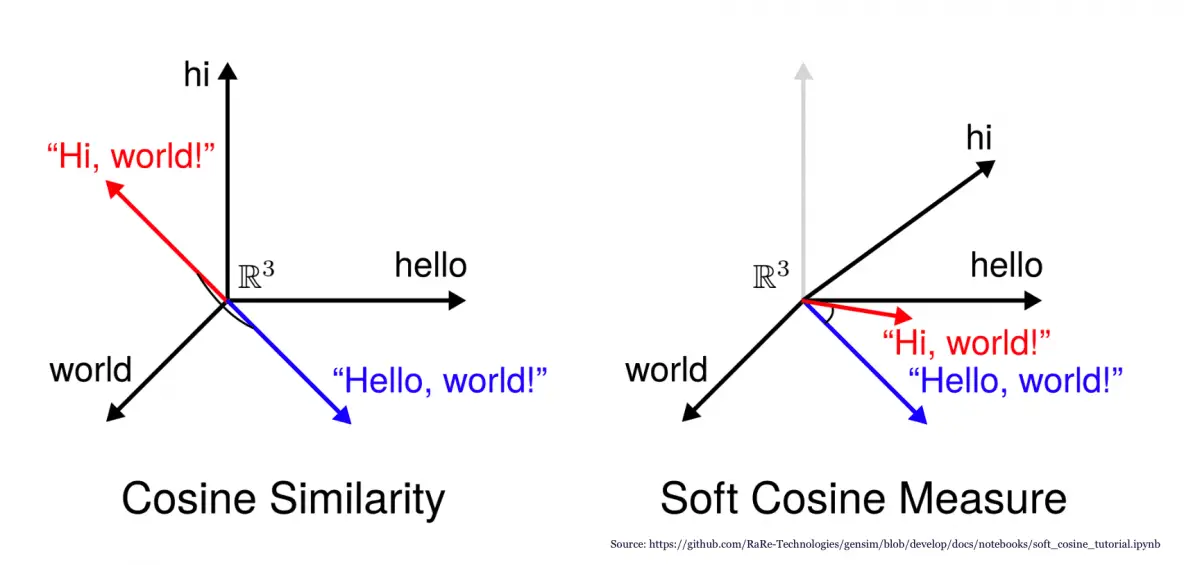
Cosine similarity search is available through many vector databases like Pinecone, Milvus, and PGVector to name a few. I chose PGVector so I can just have everything in one place. Through some indexing magic on a vector database, similarity search can be performed on a huge corpus of text very quickly. This allows AI agents to quickly find text that is relevant to a user’s question or find a cached response to a previously asked question. Think about search on steroids that doesn’t need to account for semantics, but is context and content aware.
More on choosing vector databases later…
Gathering Data
For now, most of all these theophanies came from people with a generally western or Christian view of the world.
Using Scrapy, I made a quick and dirty ChatGPT enabled web-scraper utilizing search functions on different religious websites to gather different theophanies. Additionally I gathered other visions that I had personally found interesting. Once you know the fundamentals around Scrapy, adding ChatGPT makes scraping and creating structured data out of website content a breeze.
Here’s an example of a scraper that I used. Obviously, this is not production code nor will scale, but for getting a quick job done even quicker, this will do. If a website follows a general format, ChatGPT can do that last mile of work to get the data you need separated from the cruft.
import scrapy
import openai
from dotenv import load_dotenv
load_dotenv()
client = openai.OpenAI()
class MindspiderSpider(scrapy.Spider):
name = "mindspider"
allowed_domains = [<DOMAIN_NAME_HERE>]
start_urls = [
<URL_HERE>
]
total_pages_parsed = 0
def parse(self, response):
self.total_pages_parsed += 1
if self.total_pages_parsed >= 50:
return
for link in response.xpath('//a[contains(text(), "First Vision")]'):
url = link.xpath('@href').get()
yield response.follow(url, callback=self.parse_page)
# Grab next page of search
next_link = response.xpath('//a[contains(text(), "Older posts")]')
url = next_link.xpath('@href').get()
print("Hello url!", url)
print(next_link)
if url:
yield response.follow(url, callback=self.parse)
def parse_page(self, response):
quotes = response.xpath('//blockquote//text()').getall()
title = response.xpath('//title/text()').get()
author = client.chat.completions.create(
messages=[
{
"role": "user",
"content": (f"""Given the title of an article can you tell me who it is about?
Please only say the name of the subject.
If you cannot tell, just say. no subject
for example, \"#36 Brayden Smith's First Vision\" would be Brayden Smith.
{title}""")
}
],
model="gpt-3.5-turbo",
)
full_quote = " ".join(quotes)
yield {
'author': author.choices[0].message.content,
'quote': full_quote.strip()
}
Once I gathered all the data I needed, I once again had ChatGPT generate some tags for each of the visions after which I generated some embeddings for each of the visions themselves.
Once again, it’s obvious that the tagging is not production code. The tags are cumulative over the processing run, but that visions processed earlier in the “pipeline” wouldn’t be considered to be labelled with tags that were generated later in the run. To combat this, I just ran the pipeline twice and added all the newly created tags to the labelling prompt.
import openai
import os
import glob
from dotenv import load_dotenv
load_dotenv()
client = openai.OpenAI()
from supabase import create_client, Client
url: str = os.environ.get("SUPABASE_URL")
key: str = os.environ.get("SUPABASE_KEY")
supabase: Client = create_client(url, key)
labels = [
"Mystical",
"Visual",
"Auditory",
"Sensory",
"Comforting",
"Solitary",
"Communal",
"Ceremonial",
"Crisis",
"Forgiveness",
"Guidance",
"Gratitude",
"One Personage",
"Healing",
"Nature",
"Dream",
"Fire",
"Words Spoken",
"Jesus",
"God",
"Buddha",
"Holy Spirit",
"Transformation",
"Transcendence",
"Prophetic",
"Angel(s)",
"Light",
"Fear",
"Revelation",
"Miraculous",
"Love",
"Empowerment",
"Otherworldly",
"Ethical Insight",
"Rebirth",
"Sacrificial",
"Ancestral",
"Initiation",
"War",
"Vow",
"Covenant",
"Water",
"Land",
"Sea",
"Mountain",
"Sky",
"Earth",
"Star(s)",
"Animal(s)",
"Space",
]
def read_file(file_path):
try:
with open(file_path, "r") as file:
return file.read()
except Exception as e:
return f"An error occurred while reading {file_path}: {e}"
def process_directory(parent_folder):
for directory in os.listdir(parent_folder):
dir_path = os.path.join(parent_folder, directory)
if os.path.isdir(dir_path):
for txt_file in glob.glob(os.path.join(dir_path, '*.txt')):
file_contents = read_file(txt_file)
create_entry(txt_file, file_contents)
def create_entry(path, file_contents):
# Split the string into components
parts = path.split('/')
# Extract and process the second directory for denomination
denomination = parts[1].replace('_visions', '').replace('_', ' ').title()
# Extract and process the file name for the author
file_name = parts[2].rsplit('.', 1)[0] # Remove the file extension
author_parts = file_name.split('.')
author = ' '.join([part.capitalize() for part in author_parts])
response = client.chat.completions.create(
messages=[
{
"role": "system",
"content": (f"""Given some text of spiritual or religious experience provide tags and labels for the corresponding to the text.
For example, if the text mentions a single personage appearing, provide the label \"One Personage\". If two, then provide the label \"Two Personages\". etc.
If there was explicit speaking by whatever personage, provide the label \"Words Spoken\".
Another label may be \"Light\". If a light appeared or was mentioned, provide the label \"Light\".
Here are all the labels that you can pick from. If and only if you think that a text deserves a certain unique label that cannot be associated with another existing label, may you create your own new label/tag.
{labels}
Your response should be all the tags for a passage separated by commas like so.
Light, Two Personages, Visual, Rebirth, Water
These labels will be used to filter and search for text passages in the future, so please be diligent. Match as many labels as you can.
The passage is down below.
{file_contents}""")
}
],
model="gpt-3.5-turbo",)
print(response)
tags = response.choices[0].message.content.split(", ")
embedding = client.embeddings.create(
input=file_contents,
model="text-embedding-ada-002"
).data[0].embedding
print (f"\nContents of {path}:\nDenomination: {denomination}\nAuthor: {author}\nTags: {tags}\n\nVision:\n{file_contents}\n\n")
supabase.table("visions").insert({
"author": author,
"denomination": denomination,
"tags": tags,
"content": file_contents,
"embedding": embedding
}).execute()
process_directory("visions");
I saved the final processed data in Postgres Database on Supabase using the PGVector extension. I just didn’t really want to fiddle around with hosting and deploying a database for such a small project so this was ideal.
Small Aside
If you’re on the search for a vector database that you can host yourself and is more purpose built, I would recommend Milvus. It can be deployed as a kubernetes cluster or just standalone and provides many adjustable parameters and indexes with easier configurability than PGVector. In my professional experience I use Milvus and it is more performant from my testing, but every first party vector database benchmark shows that the author’s database is the best so take that with a grain of salt 🤷
Web Interface
We’re still on the quick and dirty train, so I whipped up a vanilla React frontend with default styling, and a NodeJS Express server with some basic routes and called it a day. Frontend is hosted on Vercel, and backend is hosted on Railway.
Here are some the search capabilities that I built in.
- Search by tag
- Search semantically
- Search by cosine similarity
Also, you can input your own vision or one that you’ve found and a embedding will be generated for your text. Then using that embedding, cosine similarity returns the most similar visions within the corpus.
Prophet
In addition to all the search features, I built a prophet feature. Once again, super basic, but allows for you to find a vision within the corpus, and with other similar visions, generate a new synthetic vision.
Under the hood, this is just ChatGPT receiving this prompt:
Given these two spiritual or religious visions, generate a third that is a blend of the two.
Please copy the style the tone and the voice of the original visions as best you can, but also make the new vision unique and distinct from the originals.
Take inspiration if you will.
Here are the original visions
${visions.join("\n")}
but normies freak out when they see this sort of stuff 😅
Here are some examples:
During a momentous gathering, as I stood before the congregation delivering a eulogy, a peculiar sensation overcame me. Without any warning, a radiant golden light emerged from the back left corner of the chapel, emanating from the very heights of heaven. Though I could not physically see it, its presence was undeniable, as if it tapped into an innermost knowing. It was a sight beyond sight, one that defied our human senses. This light, without a doubt, was nothing short of the divine. I could sense the almighty presence of my creator, filling me with a profound spiritual elation.
Not long after these things passed through my mind, I ventured into the secluded forest one morning, seeking solace and clarity. With a heavy burden of timber upon my shoulder, I treaded carefully on the icy ground, my senses alert and attuned to the world around me. However, fate had other plans, and my foot slipped, causing me to stumble and become partially lodged beneath a fallen log. The timber, unrelenting, rested one end upon the log and the other upon the snow, trapping me in a predicament that seemed insurmountable. In the midst of this wretched entrapment, a radiant light emanated from the heavens, piercing not only the depths of my mind but also the depths of my heart. This divine illumination was an utterly unfamiliar sensation, one that had never graced my existence before. Within the gentle embrace of this ethereal glow, my consciousness ascended to the very throne of God and the Lamb, guided by an indescribable glory.
Start Your Own Church
I’m kinda busy right now with other things, but if you’d like, please go ahead and visit the website and start making your own AI prophesies.